I wanted to go beyond just detecting objects with YOLO and add a feature that describes the entire scene in natural language. Here’s a brief log of how I built it and the key points I focused on.
1. Why VLM?
While the existing app is great at finding specific objects using YOLO, it has limitations in explaining the overall context of a scene in full sentences. To address this, I integrated an on-device VLM that can naturally describe the entire scene in a single snapshot.
My main focus during implementation was on three things: serverless on-device execution, minimizing UI latency, and seamless Korean translation support.
2. Implementation Log
Model Selection and On-Device Porting
I selected FastVLM and SmolVLM2, both optimized for Apple Silicon. Building them for iPhone using the MLX framework was straightforward, but model loading turned out to be quite heavy. To prevent blocking the main thread, I offloaded the work using Task.detached and implemented actor-based caching for secure model container management.
UI/UX Details
It was important to provide immediate feedback to the user while waiting for results. I added a thumbnail of the captured frame to confirm what is being analyzed. I also externalized common queries into a JSON preset file, allowing users to send complex instructions with a single tap.
Translation and Security
Since the VLM outputs English, I integrated the Google Cloud Translation API. For security, I stored the API keys encrypted in the Keychain and configured Bundle ID restrictions in the Google Cloud Console to ensure the key is only usable within my app.
3. Challenges Faced
- UI Freezing: My initial async implementation still caused the screen to hang during model loading. I eventually fixed this by completely detaching the task context from the MainActor.
- API Restriction Issues: After enabling Bundle ID restrictions, requests started failing. It turns out I had to explicitly include the
X-Ios-Bundle-Identifierheader in the HTTP request.
4. Model Comparison Results
| Model | FastVLM (0.5B) | FastVLM (1.5B) int8 | SmolVLM2 (500M) |
|---|---|---|---|
| Inference (Raw) | 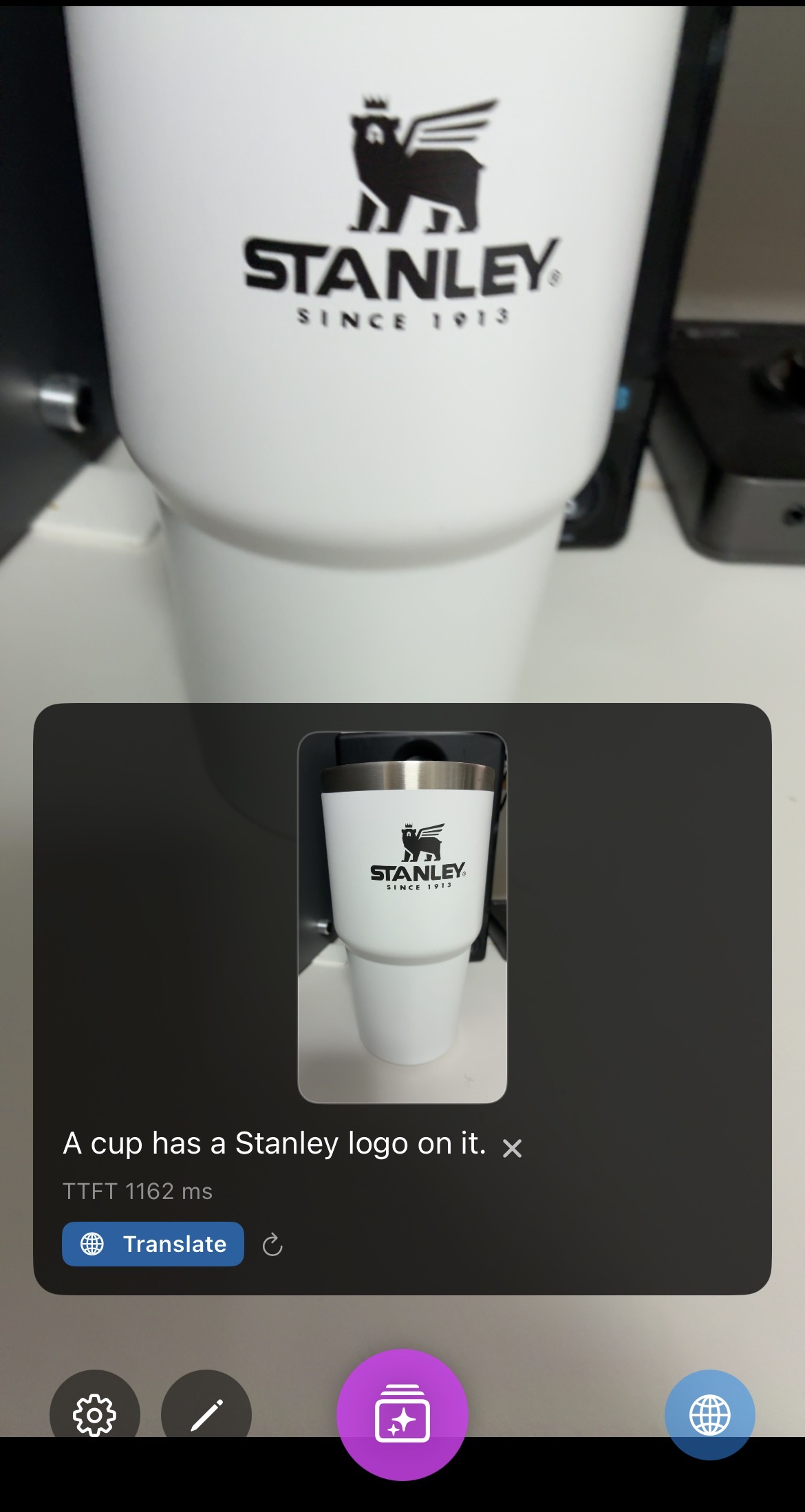 |
 |
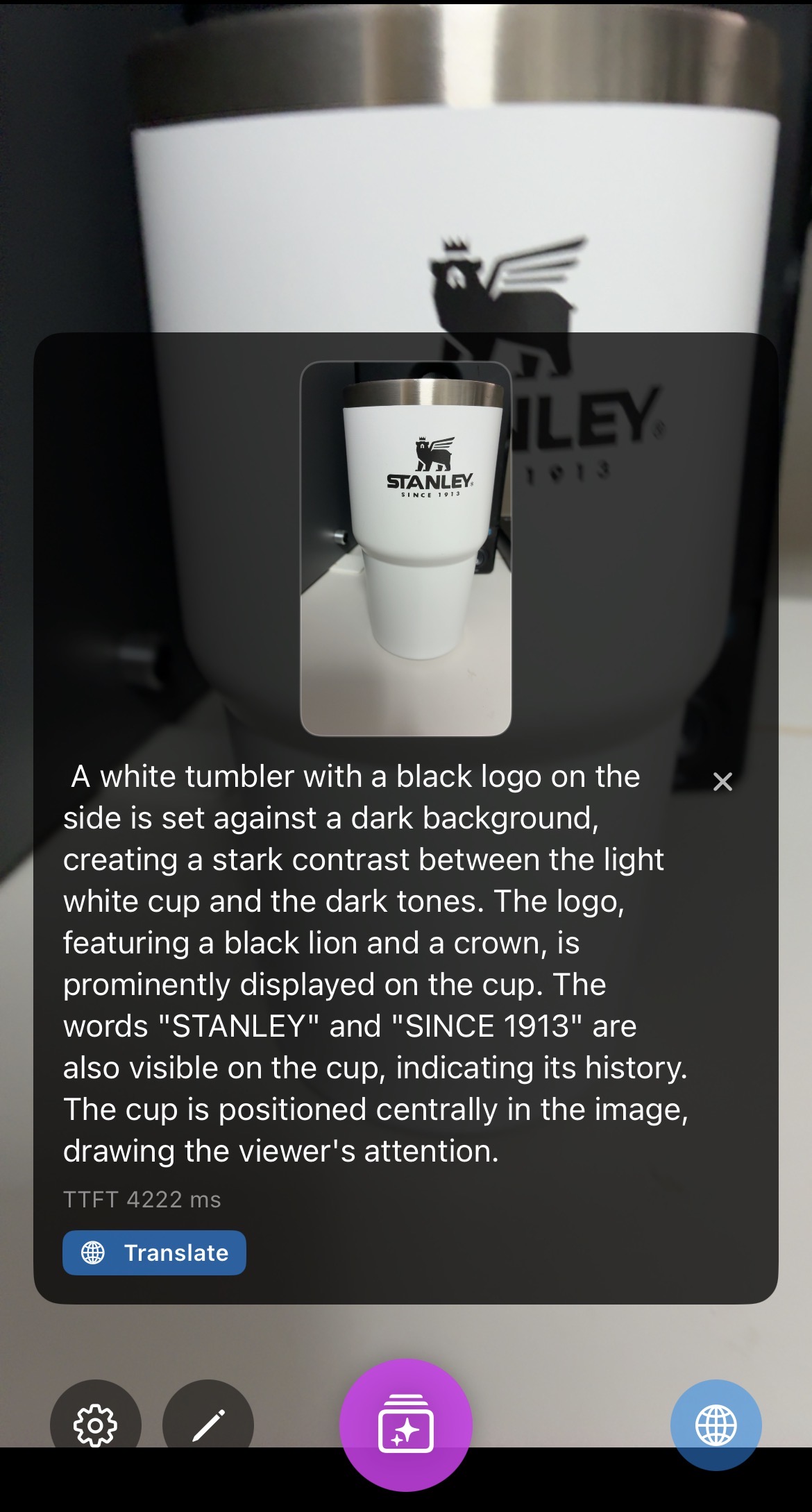 |
| Korean Translation |  |
 |
 |
- FastVLM (0.5B): Responsive. Takes about 1100ms to the first token on iPhone 16e.
- FastVLM (1.5B) int8: Enables more detailed descriptions while maintaining a fast TTFT of 1600ms. Well-balanced between memory usage and accuracy.
- SmolVLM2 (500M): Provides very detailed descriptions due to the high number of output tokens and patches, but has a slower TTFT of approximately 4200ms.