YOLO로 사물을 찾는 걸 넘어, 이제는 장면 전체를 언어로 설명해주는 기능을 붙여봤습니다. 코드보다는 구현 과정에서 고민했던 포인트와 결과 위주로 짧게 기록해둡니다.
1. 왜 VLM인가?
기존 앱은 YOLO로 객체를 잘 탐지하지만, 화면 전체 상황을 문장으로 설명하는 데는 한계가 있었습니다.
그래서 한 번의 촬영으로 장면을 자연스럽게 설명해주는 온디바이스 VLM 기능을 추가했습니다.
구현하면서는 서버 없이 동작하는 구조, UI 지연 최소화, 그리고 한국어 결과 출력 정도를 중점적으로 고려했습니다.
2. 작업 기록
모델 선정과 온디바이스 이식
Apple 실리콘에 최적화된 FastVLM과 SmolVLM2를 골랐습니다. MLX 프레임워크를 써서 iPhone에서 직접 돌아가게 만들었는데, 모델 로딩이 꽤 무겁더군요. 메인 스레드가 죽지 않게 Task.detached로 작업을 완전히 떼어내고, actor를 써서 모델 컨테이너를 안전하게 캐싱하도록 처리했습니다.
UI/UX 디테일
분석 버튼을 누르고 결과가 나올 때까지 유저가 심심하지 않게 하는 게 중요했습니다. 촬영한 순간의 프레임을 썸네일로 띄워 “지금 이걸 분석 중이다”라는 피드백을 확실히 줬고, 자주 묻는 질문들은 JSON 프리셋으로 빼서 버튼 하나로 프롬프트를 날릴 수 있게 구성했습니다.
번역 기능과 보안
VLM 결과가 영어로 나오기 때문에 Google 번역 API를 붙였습니다. API 키는 보안을 위해 Keychain에 암호화해서 저장했고, Google 콘솔에서 Bundle ID 제한을 걸어 제 앱에서만 키를 쓸 수 있게 막아뒀습니다.
3. 하면서 겪은 삽질들
- UI 멈춤 현상: 처음엔 단순하게 비동기 처리를 했다가 모델 로드 시 화면이 굳어버렸습니다. 결국 컨텍스트를 완전히 분리해서 해결했습니다.
- 번역 API 차단: 보안을 위해 Bundle ID 제한을 걸었더니 요청이 계속 씹히더군요. 알고 보니 HTTP 헤더에
X-Ios-Bundle-Identifier를 명시적으로 넣어줘야 했습니다.
4. 모델별 비교 결과
| 모델 | FastVLM (0.5B) | FastVLM (1.5B) int8 | SmolVLM2 (500M) |
|---|---|---|---|
| Inference (Raw) | 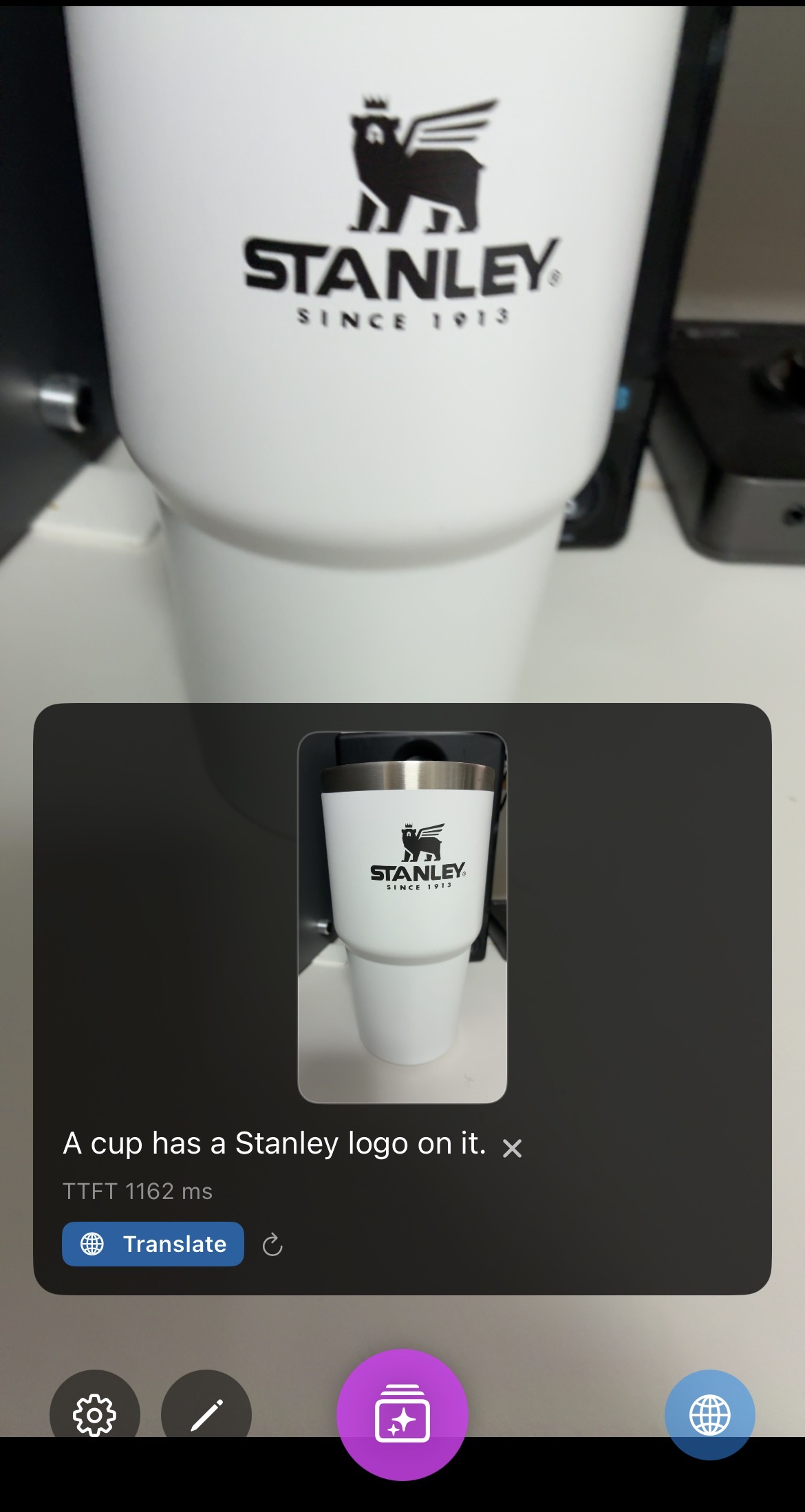 |
 |
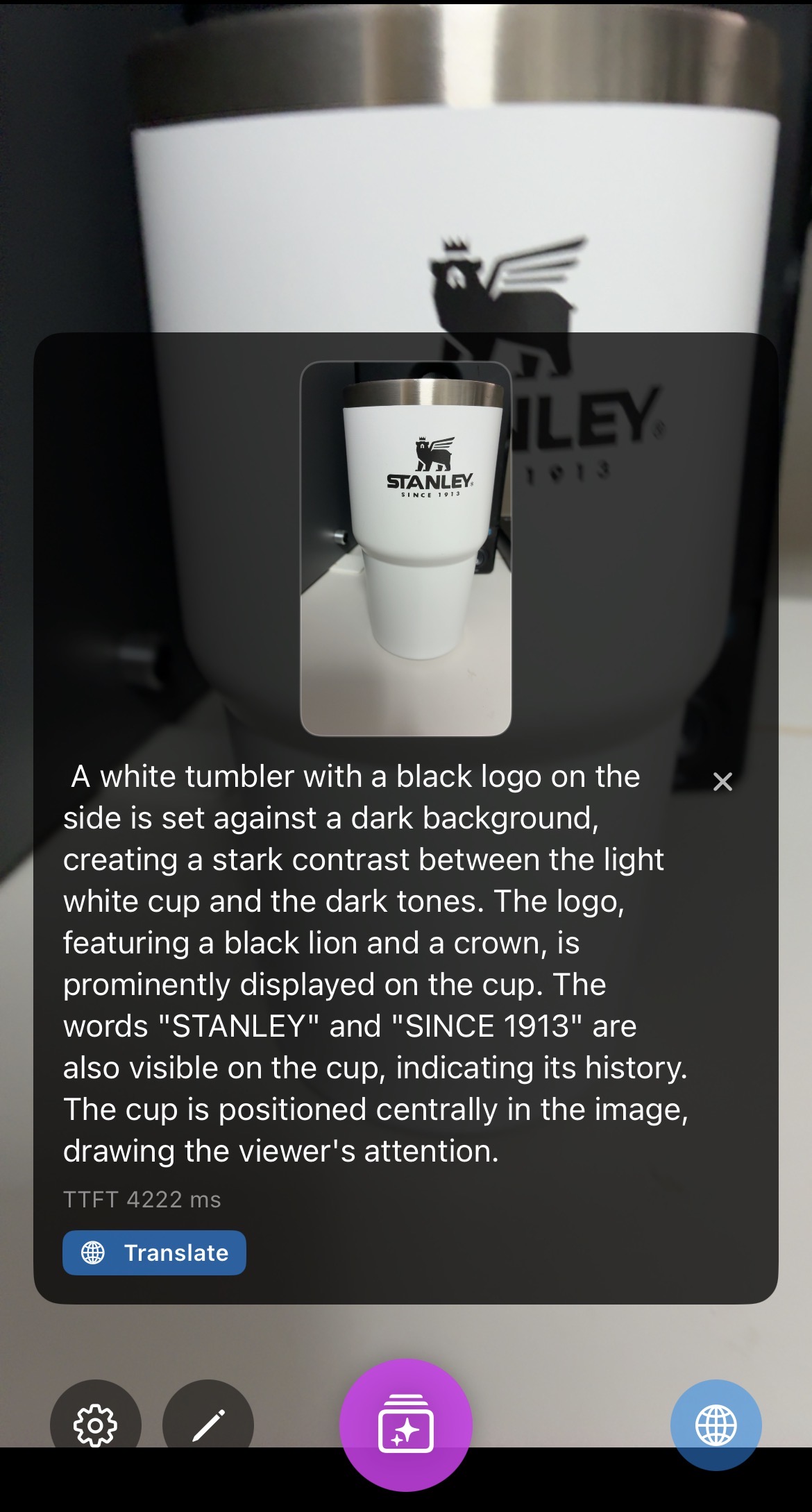 |
| Korean Translation |  |
 |
 |
- FastVLM (0.5B): 반응이 빠릅니다. iPhone 16e에서 첫 토큰까지 약 1100ms 정도 걸립니다.
- FastVLM (1.5B) int8: 1600ms의 빠른 TTFT를 유지하면서도 더 디테일한 묘사가 가능합니다. 메모리와 정확도 사이에서 균형을 잘 맞춘 느낌입니다.
- SmolVLM2 (500M): output token과 patch 수가 많아 상세한 묘사가 가능하지만, TTFT가 약 4200ms로 느린 편입니다.